
 Massachusetts Institute of Technology (MIT) araştırmacıları, yapay zeka alanında oldukça önemli bir başarıya imza attı. Kurumun geliştirdiği SEAL (Self-Adapting LLMs) adlı yeni teknik, büyük dil modellerinin (LLM) kendi kendini geliştirerek sentetik veriler üretip bunlarla kendini yeniden eğitmesini mümkün kılıyor. Böylece ChatGPT gibi sistemlerin temelini oluşturan bu modeller artık insan müdahalesine ihtiyaç duymadan performanslarını artırabiliyor.
Massachusetts Institute of Technology (MIT) araştırmacıları, yapay zeka alanında oldukça önemli bir başarıya imza attı. Kurumun geliştirdiği SEAL (Self-Adapting LLMs) adlı yeni teknik, büyük dil modellerinin (LLM) kendi kendini geliştirerek sentetik veriler üretip bunlarla kendini yeniden eğitmesini mümkün kılıyor. Böylece ChatGPT gibi sistemlerin temelini oluşturan bu modeller artık insan müdahalesine ihtiyaç duymadan performanslarını artırabiliyor. SEAL yöntemi ilk olarak Haziran ayında yayımlanan bir akademik makaleyle duyurulmuştu. Ancak geçtiğimiz ay makalenin önemli ölçüde genişletilmiş ve güncellenmiş versiyonu paylaşıldı. Ayrıca yöntem, MIT Lisansı altında GitHub’da açık kaynak olarak yayımlandı.
MIT’nin Improbable AI Lab ekibine bağlı araştırmacılar — Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim ve Pulkit Agrawal — SEAL sistemini tanıtan çalışmalarını kısa süre önce NeurIPS 2025 kapsamında sundu.
Kendini geliştiren sistemlere doğru
Geçtiğimiz aylarda ortaya çıkan SEAL, ilk aşamada yalnızca kavramsal bir çerçeveydi. Amaç, dil modellerinin kendi ürettikleri verilerle sürekli öğrenebilmesini sağlamak ve önceden eğitilmiş modellerin dağıtımdan sonra yaşadığı “bilgi durağanlığını” aşmaktı.
 Yeni versiyonla birlikte SEAL, artık yalnızca teorik bir öneri olmaktan çıktı. Araştırmacılar, sistemin model boyutu büyüdükçe daha etkin ölçeklendiğini, pekiştirmeli öğrenme (reinforcement learning) yöntemini daha verimli entegre ederek “katastrofik unutmayı” azalttığını ve çift döngülü (dual-loop) mimarisini yeniden üretilebilir hale getirdiklerini gösterdi.
Yeni versiyonla birlikte SEAL, artık yalnızca teorik bir öneri olmaktan çıktı. Araştırmacılar, sistemin model boyutu büyüdükçe daha etkin ölçeklendiğini, pekiştirmeli öğrenme (reinforcement learning) yöntemini daha verimli entegre ederek “katastrofik unutmayı” azalttığını ve çift döngülü (dual-loop) mimarisini yeniden üretilebilir hale getirdiklerini gösterdi. Bu, modellerdeki en temel bazı sorunların çözülebileceği ve ölçeklemenin sürdürülebileceği anlamına geliyor.
Tasarlanan mimari, iç döngüde denetimli ince ayar, dış döngüde ise pekiştirmeli optimizasyon aşamalarını içeriyor. Güncellenen makale ayrıca farklı istem (prompt) formatlarıyla yapılan testleri, öğrenme döngüsü boyunca artan kararlılığı ve gerçek dünyada uygulanabilirliğe dair pratik zorlukları da detaylandırıyor.
Statik modellerin sonu geliyor
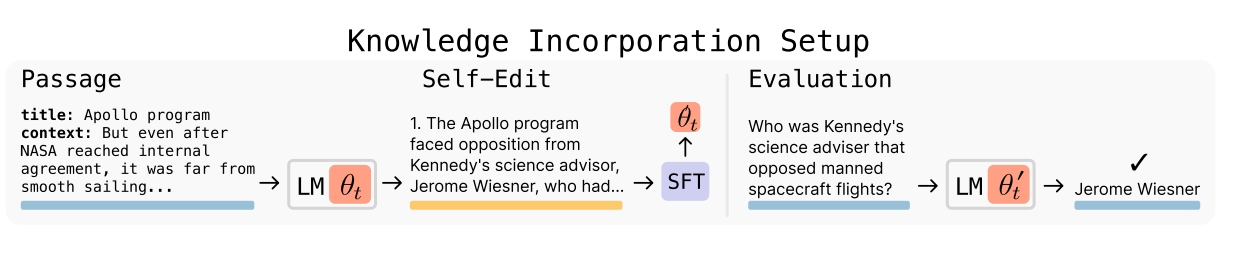
Bugün kullandığımız ChatGPT veya Gemini gibi modeller metin, görsel ve video üretiminde harikalar yaratıyor. Ancak internete bağlanıp yeni bilgileri çekmeye başladığında genellikle insan eliyle güncellemeler yapmak gerekiyor. SEAL bu sınırlamayı ortadan kaldırarak modellerin “self-edit” adı verilen kendi düzenlemelerini oluşturmasını sağlıyor.
Bu düzenlemeler, modelin hangi ağırlıkları nasıl güncellemesi gerektiğini doğal dilde belirten çıktılardan oluşuyor. Model, bu çıktılardan yola çıkarak kendini yeniden eğitiyor. Süreci yönlendiren pekiştirmeli öğrenme mekanizması, ödül sinyalini modelin görev başarımındaki artıştan alıyor.
Bu paragraf biraz karışık geldiyse hemen analojiye başvuralım. Nasıl ki bir öğrenci bilgiyi daha iyi kavramak için ders notlarını yeniden düzenliyorsa, SEAL de bilgiyi yeniden yapılandırarak daha derin bir içselleştirme sağlıyor. Bu yönüyle, dışarıdan ek veriyle “pasif biçimde” güncellenen klasik modellerden ciddi bir fark yaratıyor.
Performansta büyük artış yaşanıyor
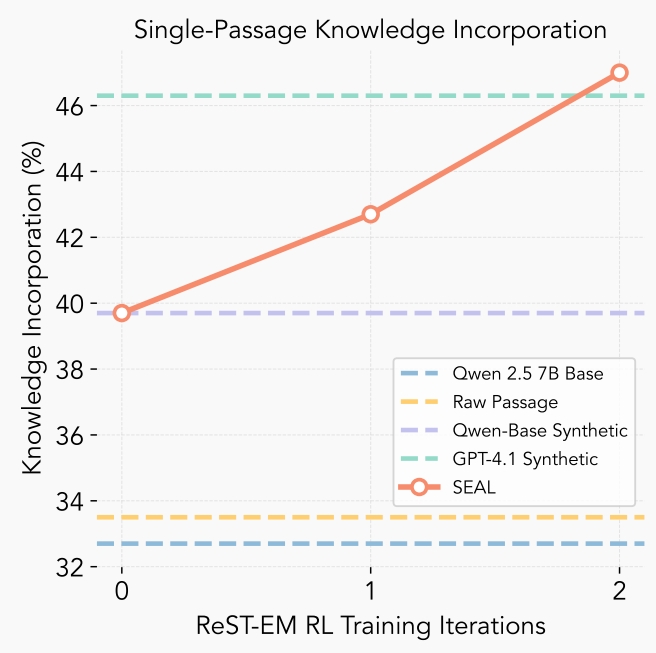
 Araştırma ekibi SEAL’i bilgi edinimi ve az örnekle öğrenme gibi iki alanda test etti. Bilgi edinimi testlerinde, modelin SQuAD (Stanford Question Answering Dataset) benzeri pasajlardan yeni bilgileri ne kadar etkili biçimde içselleştirdiği ölçüldü. SQuAD, Wikipedia tabanlı soru-cevap çiftinden oluşan bir okuduğunu anlama veri seti.
Araştırma ekibi SEAL’i bilgi edinimi ve az örnekle öğrenme gibi iki alanda test etti. Bilgi edinimi testlerinde, modelin SQuAD (Stanford Question Answering Dataset) benzeri pasajlardan yeni bilgileri ne kadar etkili biçimde içselleştirdiği ölçüldü. SQuAD, Wikipedia tabanlı soru-cevap çiftinden oluşan bir okuduğunu anlama veri seti. Bilgi edinimi testlerinde, modelin SQuAD veri setine benzer pasajlardan türettiği sentetik çıkarımlar kullanıldı. Bu yöntemle modelin doğruluk oranı yüzde 33,5’ten yüzde 47’ye yükseldi; hatta GPT-4.1’in ürettiği verilerle elde edilen sonuçları geride bıraktı.
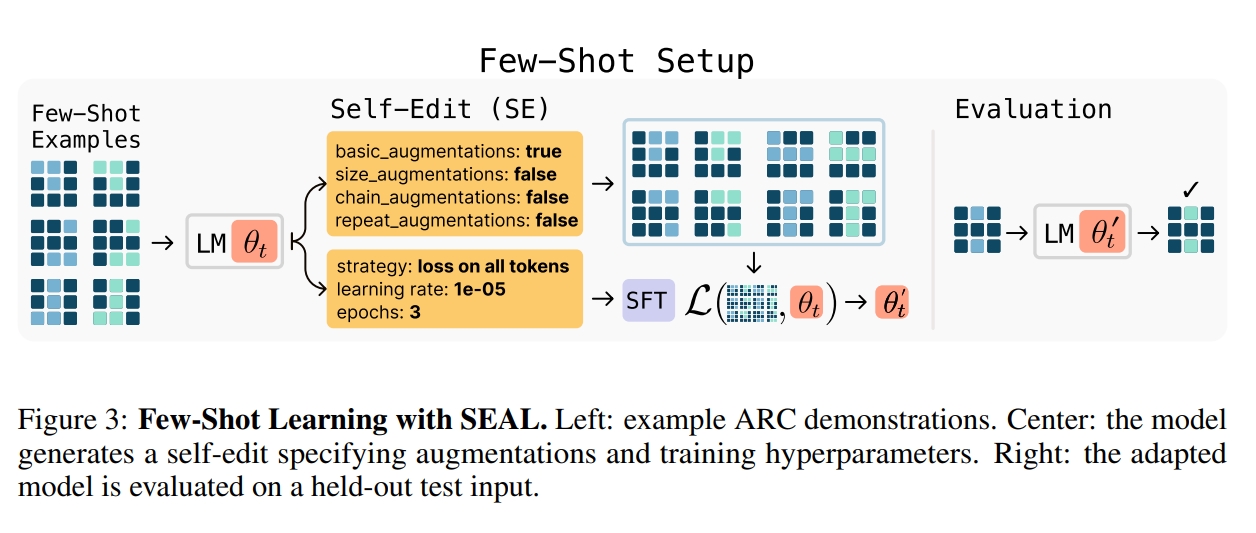 Az örnekle öğrenme testlerinde ise ARC veri setinin bir alt kümesi kullanıldı. SEAL, kendi oluşturduğu self-edit çıktılarıyla veri artırımı ve ayarlarını belirledi. Pekiştirmeli öğrenme sonrasında başarı oranı yüzde 20’den yüzde 72,5’e çıkarak, bağlam içi öğrenmeye dayalı sistemleri açık ara geride bıraktı.
Az örnekle öğrenme testlerinde ise ARC veri setinin bir alt kümesi kullanıldı. SEAL, kendi oluşturduğu self-edit çıktılarıyla veri artırımı ve ayarlarını belirledi. Pekiştirmeli öğrenme sonrasında başarı oranı yüzde 20’den yüzde 72,5’e çıkarak, bağlam içi öğrenmeye dayalı sistemleri açık ara geride bıraktı. Nasıl çalışıyor?
SEAL sistemi, çift döngülü bir mimari üzerine kurulu. İç döngü, modelin kendi oluşturduğu self-edit verileriyle denetimli ince ayar yapmasını sağlarken dış döngü, bu self-edit’leri üreten politikayı pekiştirmeli öğrenme yoluyla optimize ediyor.
 Kullanılan pekiştirmeli öğrenme algoritması ReSTEM adını taşıyor ve örnekleme ile filtrelenmiş davranış klonlamayı birleştiriyor. Eğitim sürecinde yalnızca performans artışı sağlayan self-edit çıktıları pekiştiriliyor. Böylece model, hangi düzenleme türlerinin öğrenme açısından en faydalı olduğunu kendi deneyimiyle keşfediyor.
Kullanılan pekiştirmeli öğrenme algoritması ReSTEM adını taşıyor ve örnekleme ile filtrelenmiş davranış klonlamayı birleştiriyor. Eğitim sürecinde yalnızca performans artışı sağlayan self-edit çıktıları pekiştiriliyor. Böylece model, hangi düzenleme türlerinin öğrenme açısından en faydalı olduğunu kendi deneyimiyle keşfediyor. Verimliliği artırmak için SEAL, tam parametre güncellemesi yerine LoRA tabanlı (Low-Rank Adaptation) ince ayar yöntemini tercih ediyor. Bu sayede hem deneysel döngüler hızlanıyor hem de uyarlama maliyetleri düşük kalıyor.
Zayıf karnı neresi?
Güncellenmiş çalışma, SEAL’in az gözetimle yüksek verimli eğitim verileri üretebildiğini ve bazı görevlerde GPT-4.1’i bile geride bıraktığını ortaya koyuyor. Ayrıca SEAL sayesinde daha iyi genelleme yapılabildiği de gösteriliyor. Ancak sistemin tamamen sorunsuz olduğu söylenemez.
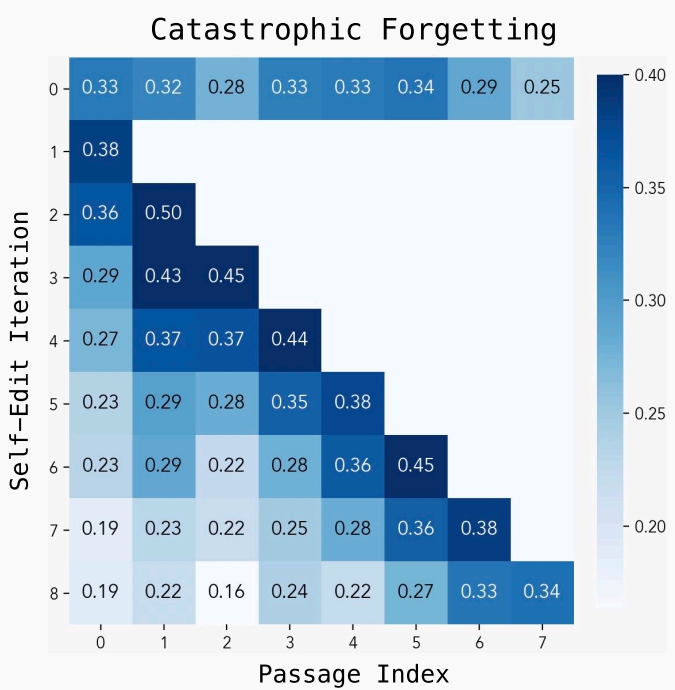 SEAL halen “katastrofik unutma” olarak bilinen probleme duyarlı, yani modele yeni bilgiler eklendiğinde eski bilgilerde bozulmalar yaşanabiliyor.
SEAL halen “katastrofik unutma” olarak bilinen probleme duyarlı, yani modele yeni bilgiler eklendiğinde eski bilgilerde bozulmalar yaşanabiliyor. Bu konuda konuşan araştırmacı Jyothish (Jyo) Pari yaptığı açıklamada, pekiştirmeli öğrenme yönteminin klasik denetimli ince ayarlamaya göre unutmayı daha iyi engellediğini belirtti. Jyo, gelecekte SEAL’in yalnızca eğitim verilerini değil, ödül fonksiyonlarını da öğrenebilen varyantlarının geliştirilebileceğini öngörüyor.
Bir diğer zorluk, sistemin hesaplama yükü. Her bir self-edit çıktısının değerlendirilmesi için modelin hem ince ayar yapılması hem de performansının test edilmesi gerekiyor. Bu da da her düzenleme başına yaklaşık 30–45 saniyelik bir işlem süresi anlamına geliyor.
Topluluk ne diyor?
Yapay zeka topluluğu ise oldukça etkilenmişe benziyor. Bazılarına göre bu, “sürekli kendini geliştiren yapay zekanın doğuşu” anlamına geliyor. Genel olarak SEAL, yalnızca yeni bilgileri özümseyen değil, öğrenme yöntemini de kendi kendine düzenleyen yapay zeka sistemlerine doğru atılmış büyük bir adım olarak görülüyor.
Araştırmacılar, gelecekte SEAL’in sürekli öğrenme, kendi kendine ön eğitim ve etkileşimli otonom ajan sistemlerinin temelini oluşturabileceğini öngörüyor. Böyle bir senaryoda, bir model her etkileşim sonrasında SEAL aracılığıyla ağırlık güncellemelerini sentezleyebilir ve davranışlarını kademeli olarak içselleştirebilir. Bu da özellikle veri kısıtlı veya özel amaçlı alanlarda, tekrar tekrar insan denetimi gereksinimini azaltabilir.


